
The Samurai Way of Managing Memory Leaks

At DPDzero, we run a data syncing service called Bifrost — a simple Python engine that syncs business data between two micro-services. It does the following:
- Read certain Parquet files from an S3 bucket
- Process them using
polars+pyarrow - Write to an Apache Iceberg db using
pyiceberg
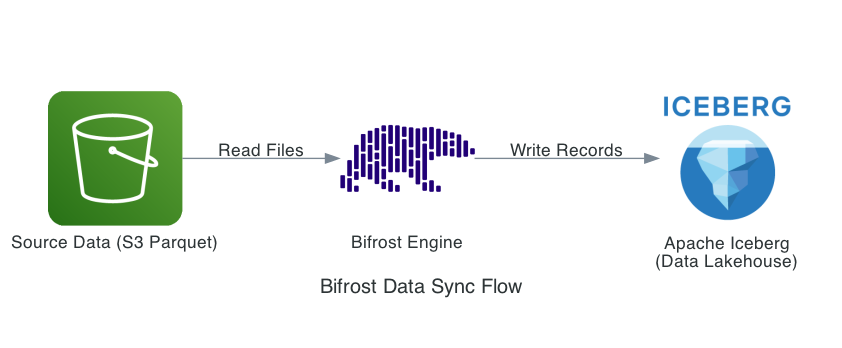
The design is simple: an infinite loop watches for changes in S3 and syncs new data into the Iceberg destination.

We run it on a Docker container inside a single EC2 instance, managed by circusd, using a basic config like this:
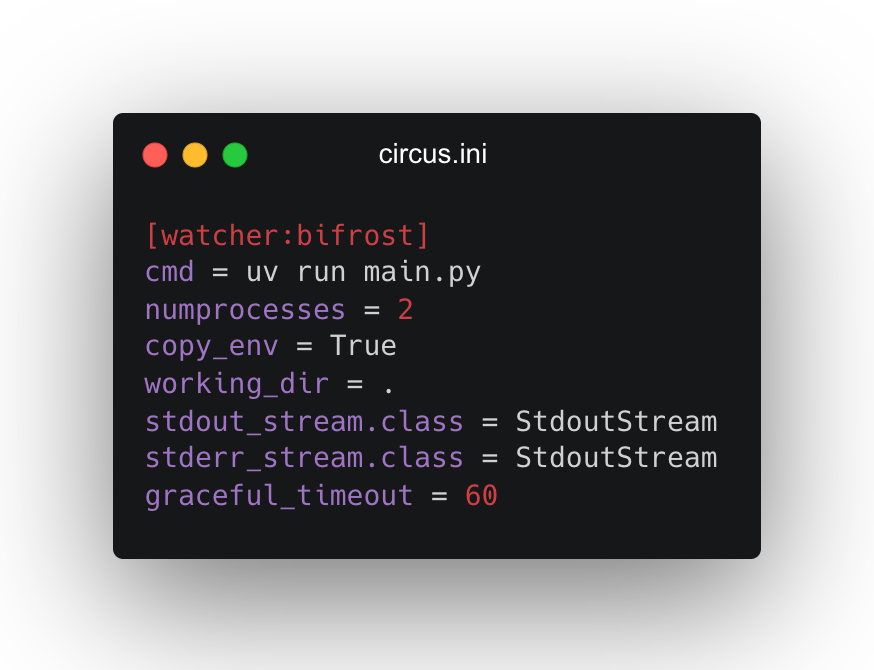
And for a while, this setup worked great. Bifrost just ran and did its job. But over time, we noticed a problem.
The Problem
Memory usage slowly crept up across both Bifrost processes. Eventually, the system would hit a breaking point — one of the processes would crash, or worse, the EC2 machine itself would become unresponsive. We had to restart it manually. Not ideal.

We suspect a memory leak, but as every engineer knows, tracking down memory leaks is hard. It requires deep profiling, experimentation, and a lot of time — something our lean team doesn’t always have.
The Fix
We took a step back and asked: Is this battle worth fighting today?
Bifrost is a fire-and-forget script. It doesn’t need to stay alive forever — it just needs to do its job reliably, and be restarted when needed.
So instead of diving into memory profilers, we reached for a simpler, time-tested solution: Process restarts.
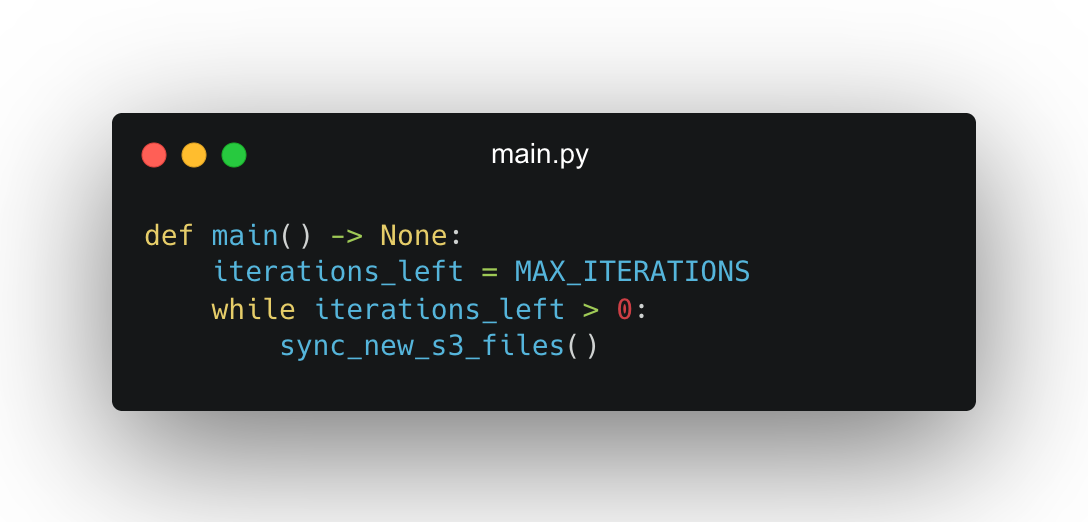
We introduced an internal counter. Every process would do a fixed number of iterations (say, 20) and then gracefully exit. circusd would then automatically restart it.
We called this approach Seppuku 🥷 — the samurai’s graceful(?) exit before things go terribly wrong.
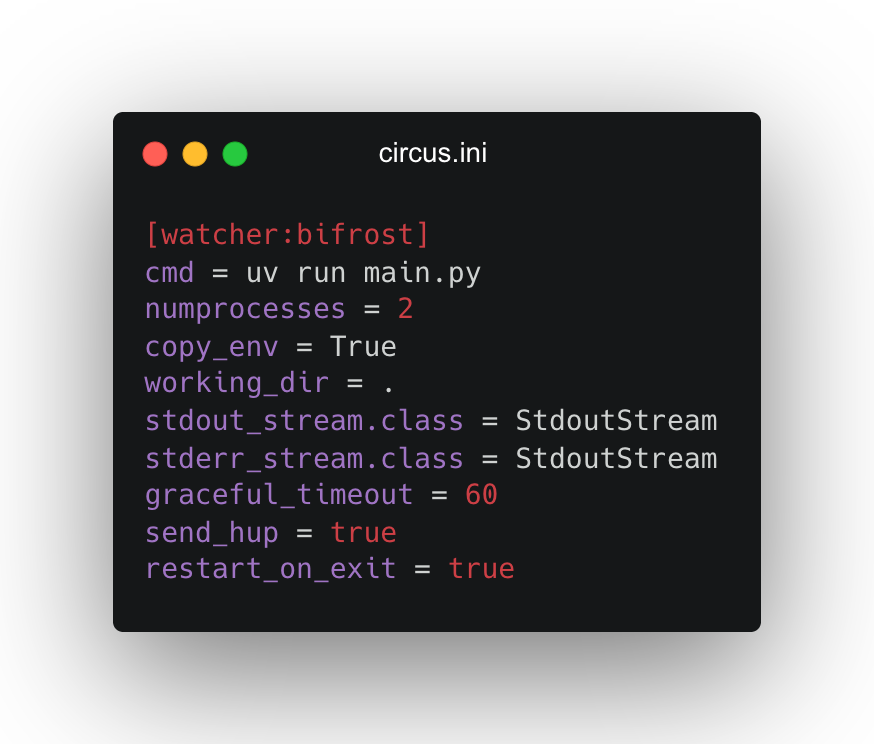
Our updated circus.ini now looks like this:
And in main.py:
The Result
With this “Samurai Strategy,” memory usage remains stable, the EC2 instance no longer crashes, and we can all sleep better at night.

This isn’t a permanent fix — and that’s okay. Sometimes, perfect is the enemy of good. When the time is right, we’ll investigate the root cause. Until then, Seppuku serves us well.